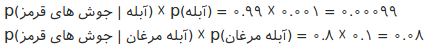
چند وقت پیش، موقع برگشت از شرکت با یکی از همکاران گفتگویی داشتیم. ایشان درباره داده های نظرسنجی جادی که هر سال به صورت آنلاین و در قالب یک پرسشنامه برگزار می شود اطلاعاتی به من دادند. این اطلاعات، با آنچه از سایر منابع می دانستم در تضاد بود. از این رو سعی کردم داده های این پرسشنامه را تحلیل کنم. بخشی از نتایج این تحلیل که در بررسی های مشابه مثل «بهداد بلاگ»، یا «تحلیل وبسایت جادی» موجود نبود مربوط به نرخ مهاجرت است. در ادامه تحلیل خود در این رابطه را به صورت مجموعه ای پرسش و پاسخ آورده ام.
۱. برای تحلیل از چه داده هایی استفاده شده است؟ برای تحلیل از داده های سال ۹۷ استفاده کرده ام که با استفاده از این آدرس می توانید آنها را دانلود کنید
۲. داده های مورد استفاده در تحلیل چند متغیر (ستون) و چند مشاهده (سطر) دارند؟ داده های مورد استفاده در تحلیل ۴۱ ستون (متغیر) و ۴۴۸۴ سطر دارند (بدون احتساب سطر مربوط به سرآیند). تعداد مشاهده های موجود در این فایل با «بلاگ بهداد» برابر است. اما در «تحلیل وبسایت جادی» این عدد ۲۹۵۷ ذکر شده (این ناسازگاری باید توسط منبع ارائه دهنده داده ها که وبسایت جادی است بررسی شود)
۳. آیا این داده ها سوگیری، یا بایاس (Bias) خاصی دارند؟ بله. مهمترین این سوگیری ها، اصطلاحا سوگیری در نمونه برداری (Sampling bias) نام دارد. یعنی برخی از افراد جامعه مقصد درصد مشارکت کمتری نسبت به جامعه واقعی دارند. از آنجا که جامعه آماری شرکت کننده گان در این پرسشنامه اکثرا از کاربران توییتر و خواننده گان وبلاگ جادی هستند، دچار یک سوگیری در نمونه گیری هستند. البته این سوگیری در تحقیقات مربوط به علوم اجتماعی بسیار رایج است
۴. سوگیری های موجود در داده ها چگونه خود را نشان می دهند؟ برای مثال از میان ۴۴۸۴ شرکت کننده تنها ۴۱۴ نفر از شرکت کننده گان (۹.۲۳٪) را خانم ها تشکیل می دهند. به علاوه اکثر شرکت کننده گان نسبتا کم سن و سال هستند.
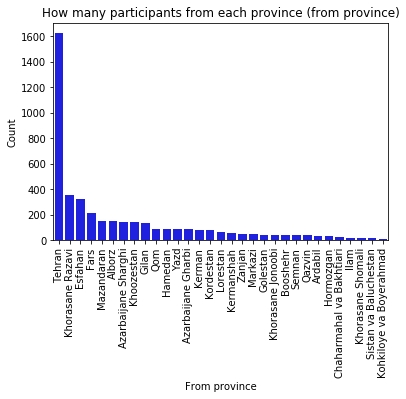
۵. از هر شهر چند شرکت کننده وجود دارد؟ داده های مربوط به این قسمت با استفاده از فیلد «خودتون رو متعلق به کدوم استان می دونید؟» به دست آمده اند.
۶. شرکت کننده گان در کدام شهرها کار می کنند؟ نمودار زیر با استفاده از اطلاعات مربوط به فیلد «استان محل کار» رسم شده است

۷. مبداء و مقصد مهاجرت برنامه نویسان ایرانی چه شهرهایی است؟ در زمان مشاهده گراف زیر این موارد را مد نظر قرار دهید (برای بزرگ کردن تصویر روی آن کلیک کنید):
- در گراف زیر اگر تعداد مهاجران از یک شهر به شهر دیگر بزرگتر یا مساوی ۲۰ نفر بوده باشد یک یال بین دو شهر رسم شده است. در نتیجه مهاجرت های کوچکتر رسم نشده اند
- شهر مقصد با نوک پیکان مشخص شده است
- تعداد مهاجران روی هر یال نوشته شده است
- حلقه (یالی از یک شهر به همان شهر نشان دهنده یکسان بودن مبداء و مقصد ذکر شده در پرسشنامه، یا عدم مهاجرت است)
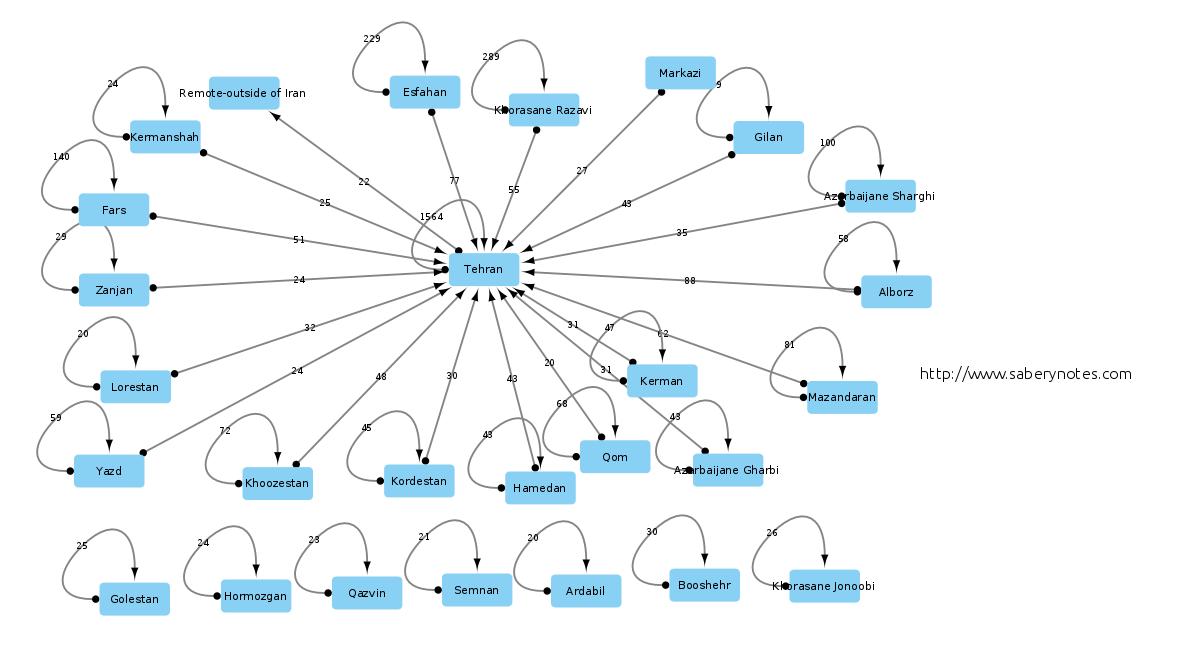
اطلاعات بسیار جالبی در این گراف قابل مشاهده است:
- تقریبا می توان گفت مقصد نهایی تمامی مهاجرت های داخلی تهران است. البته اگر در شهرهای بزرگی چون اصفهان، یا خراسان رضوی باشید محتملا به تهران مهاجرت نخواهید کرد. اما، اگر در سایر شهرها باشید وضعیت متفاوت خواهد بود
- اگر ساکن تهران باشید و قصد مهاجرت داشته باشید تنها مقصدتان کشورهای خارجی، یا دورکاری است
- برخی شهر ها هم هستند که مهاجرتی زیر ۲۰ نفر دارند، اما تعداد شرکت کننده گان آنها بزرگتر یا مساوی ۲۰ است. این شهرها در پایین گراف در قالب مجموعه ای جدا افتاده (Isolates) نشان داده شده اند
آنچه در این داده ها دیده می شود ناخوشایند است. خوب بود اگر برنامه نویسان و کارکنان آی تی مقصدی به جز تهران در مهاجرت های داخلی داشتند…
۸. در داده های موجود به طور کلی احتمال مهاجرت چقدر است؟ به طور کلی، اگر کسانی که شهر مبداء آنها مخالف شهر محل کارشان است را مهاجر فرض کنیم، و تعداد آنها را به تعداد کل شرکت کننده گان تقسیم کنیم به عدد ۰.۲۸۲ خواهیم رسید. به عبارت دیگر افراد به احتمال ۲۸ درصد برای کار مهاجرت می کنند.
البته میزان صحت این احتمال با اعتبار داده های پرسشنامه مستقیما در ارتباط است.
۹. احتمال مهاجرت از هر شهر چقدر است؟ احتمال مهاجرت از شهرهایی که بیش از ۲۰ مهاجر داشته اند در جدول زیر آمده است:
| شهر مبدا | شهر مقصد | تعداد مهاجر | احتمال مهاجرت |
| البرز | تهران | ۸۸ | ۰.۵۸۳ |
| مرکزی | تهران | ۲۷ | ۰.۵۴۰ |
| لرستان | تهران | ۳۲ | ۰.۵۰۰ |
| همدان | تهران | ۴۳ | ۰.۴۶۷ |
| کرمانشاه | تهران | ۲۵ | ۰.۴۵۵ |
| زنجان | تهران | ۲۴ | ۰.۴۴۴ |
| مازندران | تهران | ۶۲ | ۰.۴۰۸ |
| کردستان | تهران | ۳۰ | ۰.۳۶۶ |
| کرمان | تهران | ۳۱ | ۰.۳۶۵ |
| آذربایجان غربی | تهران | ۳۱ | ۰.۳۵۲ |
| خوزستان | تهران | ۴۸ | ۰.۳۳۶ |
| گیلان | تهران | ۴۳ | ۰.۳۱۲ |
| یزد | تهران | ۲۴ | ۰.۲۶۷ |
| فارس | تهران | ۵۱ | ۰.۲۴۱ |
| آذربایجان شرقی | تهران | ۳۵ | ۰.۲۴۸ |
| اصفهان | تهران | ۷۷ | ۰.۲۳۶ |
| قم | تهران | ۲۰ | ۰.۲۱۷ |
| خراسان رضوی | تهران | ۵۵ | ۰.۱۵۳ |
| تهران | ریموت-خارج کشور | ۲۲ | ۰.۰۱۴ |
همان طور که در جدول فوق هم قابل مشاهده است احتمال مهاجرت از شهرهای بزرگ مثل خراسان و اصفهان به تهران یا از تهران به خارج کشور (یا دورکاری) نسبتا اندک است.
البته می توان رابطه بین داده های مربوط به مهاجرت برنامه نویسان را با بسیاری از متغیرهای دیگر موجود در پرسشنامه بررسی کرد. برای مثال:
- آیا سن رابطه ای با مهاجرت دارد؟
- آیا رابطه ای میان میزان تخصص و مهاجرت وجود دارد؟
- جنسیت در تصمیم بر مهاجرت تاثیری دارد؟
و بسیاری موارد دیگر. متاسفانه به خاطر سوگیری داده ها نمی توان برخی از این سوال ها را پاسخ داد. برای مثال به علت پایین بودن تعداد خانم ها نمی توان به سوال رابطه بین جنسیت و مهاجرت پاسخ داد. پاسخ به سایر سوالات هم به علت قالب داده ها با دشواری هایی همراه است که به زمان زیادی نیاز دارد.
در انتها امیدوارم این تحلیل با همه کاستی هایش مفید واقع شود، و برای برخی سوالات موجود پاسخ مناسبی ارائه دهد.
برای آگاهی از پست های بعدی می توانید در کانال تلگرام وبلاگ عضو شوید.
برای عضویت در کانال وبلاگ اینجا کلیک کنید