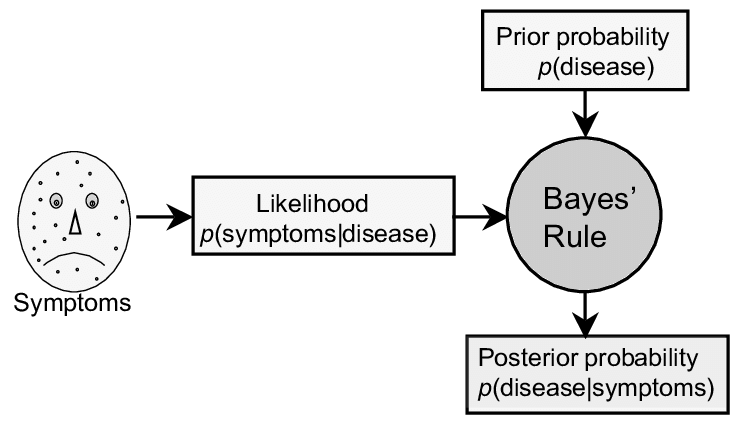
در سالهای اخیر استفاده از اسکرام (Scrum) به عنوان روشی چابک (Agile) برای توسعه نرمافزار رواج زیادی یافته. من هم مثل بسیاری از توسعهدهندگان در تیمهای چابک متعددی حضور داشتهام و شاهد پیادهسازیها و تفاسیر خوب، بد و زشت مختلفی از اسکرام بودهام.
دو سال پیش از من درخواست شد وظیفه پیادهسازی اسکرام را در یکی از تیمهای شرکت بر عهده بگیرم. در این دو سال منابع متعددی خواندم و با چالشهای زیادی مواجه شدم. سعی میکنم در این یادداشت بخشی از تجاربی که به دست آوردهام و منابعی که در این راه به نظرم مفید بودهاند را به اشتراک بگذارم.
آغاز
همه چیز خیلی عادی شروع شد. مثل همه روزهای قبل با عنوان “توسعهدهنده/محقق تکنیکی” به شرکت رفتم. آن روز با مدیر پروژه جلسه مختصری داشتم. ایشان از من خواستند به علت پارهای از مشکلات و درخواست اعضای تیم به سراغ اسکرام برویم. به علاوه، پیشنهاد دادند کتاب Essential Scrum: A practical guide to the most popular agile process اثر Kenneth Rubin را برای آشنایی هر چه بیشتر با اسکرام بخوانم. مدتها قبل از این روز، کتاب Agile اثر Bertrand Meyer را خوانده بودم (که باید اعتراف کنم تا حدی کسالت آور، اما بسیار ارزشمند است). با پیش فرض کسالت آور بودن کتاب Rubin به مطالعه آن پرداختم. منبع بسیار خوبی بود و بر خلاف تصور من بسیار جذاب بود. این منبع دانش کافی برای آغاز پیاده سازی اسکرام را در اختیارم قرار داد. اما پیش از آغاز پیاده سازی سوالی برایم مطرح بود: چرا اعضای تیم درخواست استفاده از اسکرام را داده بودند؟
مصاحبه و مشخص شدن روند شکست کارها
برای پاسخ به این سوال که: “چرا اعضای تیم درخواست استفاده از اسکرام را داده بودند؟”؛ مصاحبهای با آنها ترتیب دادم. هر چه باشد در کارشناسی ارشد مدتی را صرف یادگیری تفکر طراحی (Design Thinking) کرده بودم (برای آشنایی بیشتر با تفکر طراحی میتوانید به این پست وبلاگ مراجعه کنید). مهمترین پیام تفکر طراحی همدلی (Empathy) و حل مشکل واقعی کاربران یک سیستم است. در این مصاحبه نکات خوبی از مشکلات تیم به دست آوردم:
- افراد دوست داشتند تصویر کلی آنچه در حال اتفاق افتادن است را در اختیار داشته باشند
- اعضای تیم دوست داشتند با هم تعاملات بیشتری داشته باشند (تیمتر باشند)
- آنها دوست داشتند در بازههای زمانی مشخصی که کوتاهتر از چند ماه است بازخورد کارهایشان را از مشتریها/ذینفعان دریافت کنند
- افراد دوست داشتند مکانیزمی در اختیار داشته باشند تا مشکلاتشان را در بازههای زمانی مشخص به گوش بقیه برسانند
- و …
نتیجه مصاحبه مرا تا حدی قانع کرد که اسکرام ممکن است بتواند بعضی از این مشکلات را حل کند.
بعد از مصاحبه سراغ پیادهسازی اسکرام رفتم. برای آنکه مفاهیم کتاب Rubin را فراموش نکنم یک MindMap از کتاب تهیه کردم تا هر وقت با ابهامی مواجه میشوم به آن رجوع کنم.
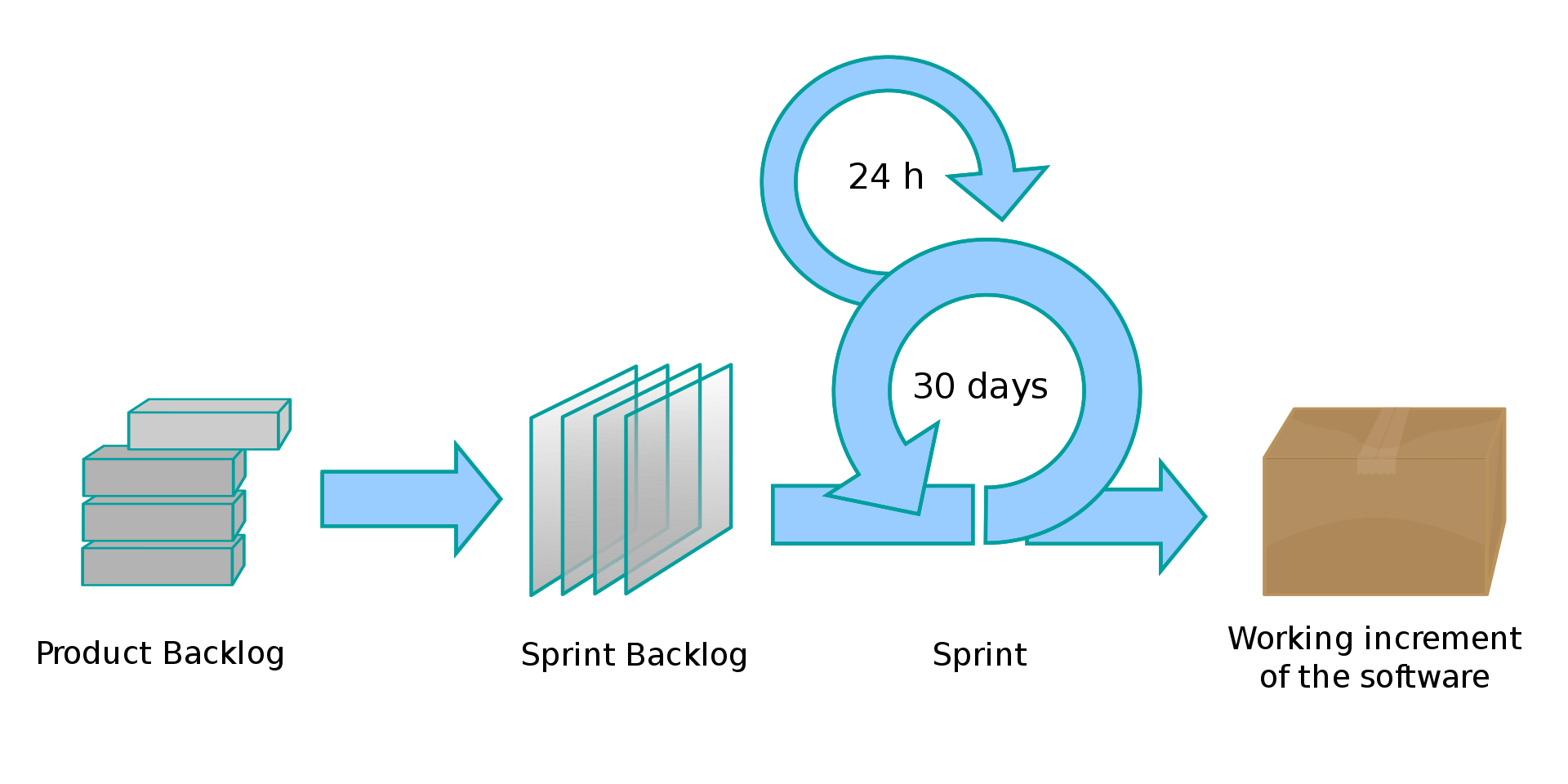
برای پیاده سازی اولیه لازم بود روند شکستن پروژه و چگونگی مستندسازی نیازمندیها را مشخص کنم. اسکرام استاندارد مشخصی برای مستندسازی نیازمندیها ندارد. در اکثر منابع از جمله Rubin پیشنهاد شده از User Story ها بدین منظور استفاده شود. برای اینکه با User Storyها آشنا شوم به منبع دیگری مراجعه کردم: User Stories Applied اثر Mike Cohn. نویسنده در این کتاب به خوبی نحوه استفاده از User Storyها را شرح می دهد. در ادامه ساختاری چهار سطحی برای شکستن پروژهها طراحی کردم. در این ساختار هر پروژه به مجموعهای اپیک (Epic) میشکند. هر اپیک که خود یک User Story درشتدانه است به مجموعهای Story ریزدانهتر شکسته میشود. هر Story باید به اندازهای باشد که در یک اسپرینت قابل انجام است. در ادامه، هر Story برای پیاده سازی به مجموعهای Task شکسته می شود.
اما اپیکها، استوریها و تسکها را چگونه باید تخمین زد؟ برای یافتن پاسخ این سوال مجبور شدم دو منبع دیگر را هم بخوانم. یکی کتاب Agile Estimating and Planning اثر Mike Cohn و دیگری کتاب Return on Software اثر Steve Tockey. با خواندن این دو کتاب با اصول و روشهای تخمین کارها به خوبی آشنا شدم. در ادامه، برای تخمین اپیکها T-Shirt Size، استوریها Story Points و تسکها ساعت ایده آل را برگزیدم.
باید اعتراف کنم تخمین (Estimation) کارها با این واحدها عموما فرایندی دشوار و گاها مبهم است. البته این ابهام در ذات هر تخمینی نفهته است (به علت رابطه بین دانش و احتمال). اما به نظر میرسد تعریف این واحدها و به خصوص استوری پوینت گاهی به این ابهام دامن میزند. برای مثال، کوهن در سال 2004 در کتاب خود میگوید بهتر است هر استوری پوینت معادل یک روز کاری ایده آل باشد (پاراگراف آخر صفحه 87). در ادامه کوهن در سال 2005 در کتاب دیگرش روز ایده آل را به کل از استوری پوینت جدا می کند و میگوید ترجیح میدهد از استوری پوینت به عنوان معیاری برای پیچیدگی کارها استفاده کند (پاراگراف اول صفحه 75). در ادامه سایر نویسنده ها مثل لفینگول تعریف متفاوت تری از استوری پوینت ارائه میدهند. برخی دیگر مثل واکانتی به کل متریک های مبتنی بر استوری پوینت را زیر سوال میبرند و …
در نهایت باید بگویم در دو منبع فوق تئوری تخمین زدن به میزان خوبی تشریح شده اما استفاده از آنها در عمل به طور کلی با آنچه ممکن است بیندیشید تفاوت دارد. تقابل این تئوریها و عمل مرا به یاد این جمله میاندازد: عمل همیشه به تئوری میخندد (یادم نیست این سخن از کدام فیلسوف است).
فلسفه اسکرام برای انجام کارها
پیش از ادامه شاید بد نباشد نگاه فلسفی اسکرام به چگونگی انجام کارها را کمی تشریح کنم. این بررسی، چرایی این همه جلسه و تخمین و … را روشنتر میکند. به طور کلی اسکرام فرض میکند توسعه نرمافزار فرآیندی غیر قابل پیشبینی است (بررسی میزان صحت این فرض از حوصله این یادداشت خارج است). این غیرقابل پیشبینی بودن باعث میشود آموزههای روشهایی مثل روش آبشاری (Waterfall model)، که سعی میکنند در ابتدای پروژه کارها را به صورت دقیق بشکنند و تخمینی برای آنها ارائه دهند، در توسعه نرمافزار بیفایده شود. در عوض اسکرام سعی میکند برای انجام کارها روشی مشابه الگوریتم گرادیان کاهشی (Gradient Descent) برگزیند (برای اطلاعات بیشتر درباره این الگوریتم میتوانید به این کتاب رایگانی که درباره شبکههای عصبی ترجمه کردهام مراجعه کنید).
اجازه دهید با مثالی روش اسکرام را توضیح دهم. فرض کنید بالای تپهای هستید. هوا تاریک است و فقط چند متر جلوتر را میبینید. میخواهید از تپه پایین بیایید؛ چه میکنید؟ هدفتان مشخص است: پایین آمدن. به علاوه، به طور کلی میدانید برای پایین آمدن از تپه باید به سمت سراشیبی حرکت کنید. درنتیجه، به مرور با انتخاب سراشیبیهای اطرافتان پایین میآیید. در طول مسیر باید توقفهایی هم داشته باشید و وضعیتتان را ارزیابی کنید. شاید مسیر را اشتباه آمدهاید و مجبور شوید برگردید و تغییر مسیر دهید.
اسکرام هم دقیقا از همین روش بهره میبرد: پروژهای با چشمانداز (هدف) مشخص داریم؛ این چشم انداز را به مجموعهای نیازمندی درشت دانه (برای مثال اپیک) تقسیم میکنیم. با افزایش دانشمان از پروژه و با اولویت بندی کارها طبق نیازهای مشتری این نیازمندیهای درشت دانه را به نیازمندیهای ساده تر میشکنیم. هر اسپرینت بخشی از این نیازمندیهای ریزدانه را انجام میدهیم (قدمهای کوچک در جهت سراشیبی یا رسیدن به هدف). سپس بررسی میکنیم آیا در جهت درستی در حال حرکت هستیم یا خیر؟ در صورت لزوم تغییر مسیر میدهیم (ارزیابی وضعیت). هر یک از این مراحل را میتوان به یکی از رویدادهای اسکرام نگاشت کرد.
البته تئوریها و مطالعات فراوانی پشت این روش ساده نهفته است. برای اطلاعات بیشتر در این باره میتوانید از این پست وبلاگ شروع کنید.
توجه داشته باشید اسکرام برای هر پروژهای مناسب نیست. برای اطلاعات بیشتر میتوانید به کتاب Rubin و منابع مربوط به چهارچوب Cynefin مراجعه کنید. هرچند گاهی منابع مربوط به چهارچوب Cynefin هم آنقدر شفاف نیستند …
جلسات اسکرام و چالشهای آنها
طبق آنچه در منابع مختلف خواندم اسکرام چند جلسه اصلی دارد:
- جلسات پلنینگ (Planning): هدف این جلسات برنامه ریزی برای کارهایی است که در طول اسپرینت انجام میشود
- جلسات روزانه (Daily): هر روز جلسهای با عنوان Daily Standup برگزار میشود. در این جلسات اعضای تیم درباره کارهایی که باید در آن روز انجام شود با هم هماهنگ میشوند
- جلسات بازبینی (Review): در انتهای هر اسپرینت یک جلسه بازبینی برگزار میشود. در این جلسات کارهای انجام شده در طول اسپرینت برای ذینفعان اصطلاحا دمو میشود و تیم توسعه بازخوردهای مربوطه را دریافت میکند. به علاوه، اگر نیازی به تغییر جهت انجام کارها باشد در این جلسات بحث و گفتگویی شکل میگیرد
- جلسات رترو (Retrospective): در انتهای هر اسپرینت یک جلسه رترو برگزار میشود. در طول این جلسه اعضای تیم به بررسی اسپرینت قبل و مشکلاتی که حین انجام کارها با آن مواجه شدند میپردازند و سعی میکنند راهکارهایی برای حل برخی از این مشکلات در اسپرینتهای آینده بیابند. در نتیجه، جلسات رترو مکانیزمی برای اصلاح فرآیند انجام کارها در اختیار اعضای تیم قرار میدهد
توجه داشته باشید که اسکرام دو مکانیزم اصلاح دارد: یکی برای بهینه سازی و اصلاح خروجی کار (جلسات بازبینی) و دیگری برای بهینهسازی فرآیند رسیدن به هدف.
توضیحات فوق را در هر کتاب یا منبع اسکرامی میتوانید بیابید. اما چیزی که در اکثر این منابع به درستی مشخص نیست نحوه اجرای این جلسات است! برای مثال، ممکن است ایده برگزاری جلسات روزانه به نظر جذاب بیاید. اما وقتی سعی میکنید افراد را گرد هم آورید با مشکلات متعددی در این باب مواجه خواهید شد (به خصوص در دورکاری). در این باره هر کسی نظری دارد و نظر هیچ کس هم وحی منزل نیست. به طور کلی می توانید جلسات روزانه را به سه روش برگزار کنید:
- همگام و حضوری: همه در یک ساعت مشخص به صورت حضوری در مکانی مشخص برای برگزاری جلسه حاضر میشوند
- همگام و آنلاین: همه در یک ساعت مشخص در یک ابزار چت صوتی/تصویری برای برگزاری جلسات حاضر میشوند
- ناهمگام: در این روش همه در یک ساعت مشخص برای جلسه حاضر نمیشوند. بلکه هر کسی در ساعت متفاوتی مطالب خویش را در یک سیستم چت مینویسد
برای اطلاعات بیشتر درباره روشهای همگام و غیرهمگام میتوانید به این مقاله مراجعه کنید.
برگزاری جلسات پلنینگ و بازبینی هم چالشهایی دارد (ممکن است در آینده در یک پست جداگانه به آنها بپردازم). اما، برگزاری آنها آنقدرها هم دشوار نیست. در این میان، گنگ ترین جلسه، جلسه رترو است. هیچ یک از منابعی که خواندم به درستی به بررسی ساختار این جلسات نمیپردازند. به علاوه، طبق آنچه فهمیده بودم این جلسه اهمیت زیادی داشت. در نتیجه، کتاب Agile Retrospectives اثر Derby و سایرین را خواندم. با خواندن این کتاب با ساختار جلسات رترو به خوبی آشنا شدم و توانستم فرآیند آن را درک کنم.
تئوری و عمل
تا اینجا منابع بسیاری خوانده بودم و میتوانستم با آنچه میدانم اسکرام را به خوبی پیادهسازی کنم. در نتیجه، کار را شروع کردم و شدم اسکرام مستر تیم. در پیاده سازی و اجرای فرآیند مشکل خاصی نداشتم اما با شروع کار متوجه خلاء بزرگی در دانش خود شدم که در هیچ یک از منابع (به جز کتاب Derby و سایرین درباره جلسات رترو) به آن اشارهای نشده است: نحوه تعامل با افراد بدرفتار! سخت ترین و حساس ترین قسمت کار هم همین جاست.
اسکرام اولین تجربه مدیریتی من نبود اما تعریف نقش اسکرام مستر و اختیارات آن تفاوت محسوسی با نقشی مثل مدیر فنی دارد. در نتیجه، ساختار و پویایی قدرت در اسکرام بسیار متفاوت است. به علاوه، اسکرام تاکید زیادی بر تیم دارد. تیم نسبت به استرس و بدرفتاری موجودی بسیار حساس است. در نتیجه، تصمیماتی که درباره برخورد با افراد بدرفتار میگیرید ممکن است در اسکرام عواقب متفاوتی داشته باشد …
متاسفانه در ادبیات اسکرام راهکار خاصی برای تعامل با “افراد بدرفتار” وجود ندارد. اسکرام فرض میکند همه اعضای تیم مطیع هستند و کاری بر خلاف هدف تیم، و سازمان انجام نمیدهند. در اندک مواردی که اشارهای به نحوه تعامل با افراد بدرفتار شده است هم راهکار به سیب گندیده (Bad Apple) خواندن آنها، تذکر و نهایتا اخراجشان ختم میشود. برای مدتی این سوالات ذهن مرا به شدت مشغول کرده بود:
- با افراد بدرفتار چه باید کرد؟
- آیا تنها راهکار طرد فرد از گروه و سازمان است؟ اگر چنین نیست تا چه مدت باید با افراد بدرفتار مدارا کرد؟
- آیا چنین تصمیمی (که مسلما خارج از وظایف اسکرام مستر است اما وی هم در آن نقش دارد) اخلاقی است؟
- پس کسانی که نمیتوانند در چهارچوبی مثل اسکرام کار کنند چه؟
برای پاسخ این سوالات به فیلدهای مطالعاتی متعددی از جمله فلسفه اخلاق، نظریه تصمیم (Decision Theory) و روان شناسی مراجعه کردم. البته از قبل هم در برخی از این زمینهها مطالعات قابل توجهی داشتم. این سوالات مرا بر آن داشت به طور خاص در این منابع دنبال پاسخ باشم. برخی از کتبی که در این راستا خواندم عبارتند از کتاب Exploring Ethics اثر Steven Cahn، برخی از کتب اروین یالوم و کتاب An introduction to decision theory اثر Martin Peterson. مسلما خواندن این کتب خالی از لطف نبودند اما پاسخ خاصی هم در اختیارم قرار ندادند.
گاهی به عنوان اسکرام مستر باید تصمیماتی بگیرید که صورت آنها بی شباهت به مسئله تراموا (Trolley Problem) نیست. در این میان نظریه تصمیم هم کمک زیادی نمیکند زیرا عقلانیت (Rationality) یک تصمیم در موقعیتی خاص به هدفتان بستگی دارد (به این ویژگی اصطلاحا Instrumental Rationality میگویند). طبق تعاریف اقتصادی هدف کارکنان یک سازمان باید در راستای اهداف آن سازمان یعنی رسیدن به ماکزیمم سود (و کاهش هزینه) باشد. در نتیجه، ممکن است طبق هدف سازمان و تحلیلهای نظریه تصمیم به نتیجهای برسید که در راستای هدف سازمان عقلانی است اما اخلاقی نیست و شما را راضی نمیکند…
در نهایت باید بگویم (با دانش فعلیام) عموما مسائل انسانی راه حل ریاضی ندارند و همان طور که در این پست به صورت مفصل شرح داده ام راه حلهای این مسائل همه را راضی نخواهد کرد.
نقاط ضعف اسکرام
اسکرام نقاط ضعف متعددی دارد. این نقاط ضعف بدین معنی نیستند که اسکرام فرآیند بدی است. هر ابزاری مزایا و معایبی دارد. در ادامه برخی از آنها را آوردهام:
- این روش فرض میکند افراد به کار تیمی علاقه دارند (طبق مشاهدات من خیلی وقتها چنین نیست!)
- در اسکرام فرض شده شما تیمی از افراد متخصص دارید. پیدا کردن متخصص در حال حاضر در کشورهای پیشرفته هم با چالشهایی رو به رو است
- ادبیات اجایل گاها ضد و نقیض است و شواهد درستی برای ادعاهایش ندارد. این نکته را برتراند میر به بهترین شکل ممکن در نقد خود از این روش ها در کتابش بیان کرده. پیشنهاد می کنم حتما این کتاب را بخوانید
- اساسی ترین نقطه ضعف اسکرام از نظر من خود تیم است. تیم ماهیتی بسیار شکننده دارد. حتی تاکمن (Tuckman) هم در مقاله خود به این مسئله اشاراتی دارد
- نگاه اسکرام به برنامهنویسها در نهایت به یک دیدگاه تیلوریستی منتهی خواهد شد (به خصوص با تجمیع روشهایی مثل تفکر طراحی با اسکرام). شرح کامل این مشکل را میتوانید در این مقاله بخوانید
- جلسات متعدد اسکرام عموما برای افراد خستهکننده است (هرچند برگزاری این جلسات لازم است)
- برای استفاده از اسکرام نیاز به آموزش نسبتا طولانی به افراد تیم وجود دارد
- از نظر من فرض تعهد اعضای تیم به انجام کارها در موقعیتهای زیادی قابل قبول نیست
- روشهای اجایل مجموعهای Technical Practice دارند که اگر به درستی در کدنویسی استفاده نشوند خروجیهای عجیب و غریبی به شما خواهند داد. یادگیری این Technical Practiceها توسط اعضای تیم زمانبر است
- برای پیادهسازی اسکرام منبع جامعی وجود ندارد و باید اطلاعات لازم را مانند تکههای یک پازل از منابع مختلف و پراکنده گرد هم آورید (هرچند بعضی این را نقطه قوت اسکرام میدانند)
- رعایت نظم در اسکرام اهمیت بسیار زیادی دارد. بینظمی یکی از اعضا میتواند ضربات قابل توجهی به فرآیند وارد آورد
- اسکرام کسانی که روحیه کار تیمی ندارند را به کلی کنار میگذارد
نقض هر یک از این مفروضات شما را با مشکلات متعددی مواجه خواهد ساخت…
نتیجهگیری
در نهایت باید بگویم اسکرام چاره همه مشکلات نیست. اما راه حلهای معقولی برای برخی از آنها فراهم میآورد. هرچند این راه حل ها هزینههایی هم دارند. برای استفاده از این روش باید صبور و مشتاق به یادگیری باشید. باید بیش از هر حسی، حس همدلی با اعضای تیمتان را تقویت کنید. چون تنها راه کنار هم ماندن در روزهای سخت همین حس همدلی و همدوستی است.
در نهایت امیدوارم این یادداشت برایتان مفید باشد.
برای آگاهی از پست های بعدی می توانید در کانال تلگرام وبلاگ عضو شوید.
برای عضویت در کانال وبلاگ اینجا کلیک کنید